- テキスト(記事のテーマ)を受け取る
- グーグルからトップ3のランキング検索結果を取得する
- 生データから必要な情報だけを取り出し、データをクリーンな状態にする
- トップ3のURLから文章のHTMLを取り出します
- 検索結果のURLリストから実際のページ内容を取得する
- 4と同様
- HTMLから必要なテキストやデータを取り出し、不要な部分を削除して整える
- ループで取得した複数のページの本文テキストを1つにまとめる
- グーグルが高く評価している事実情報の抽出と記事の要約
- 最終記事生成
- 生成した記事を、任意のグーグルドキュメントのファイルに保存
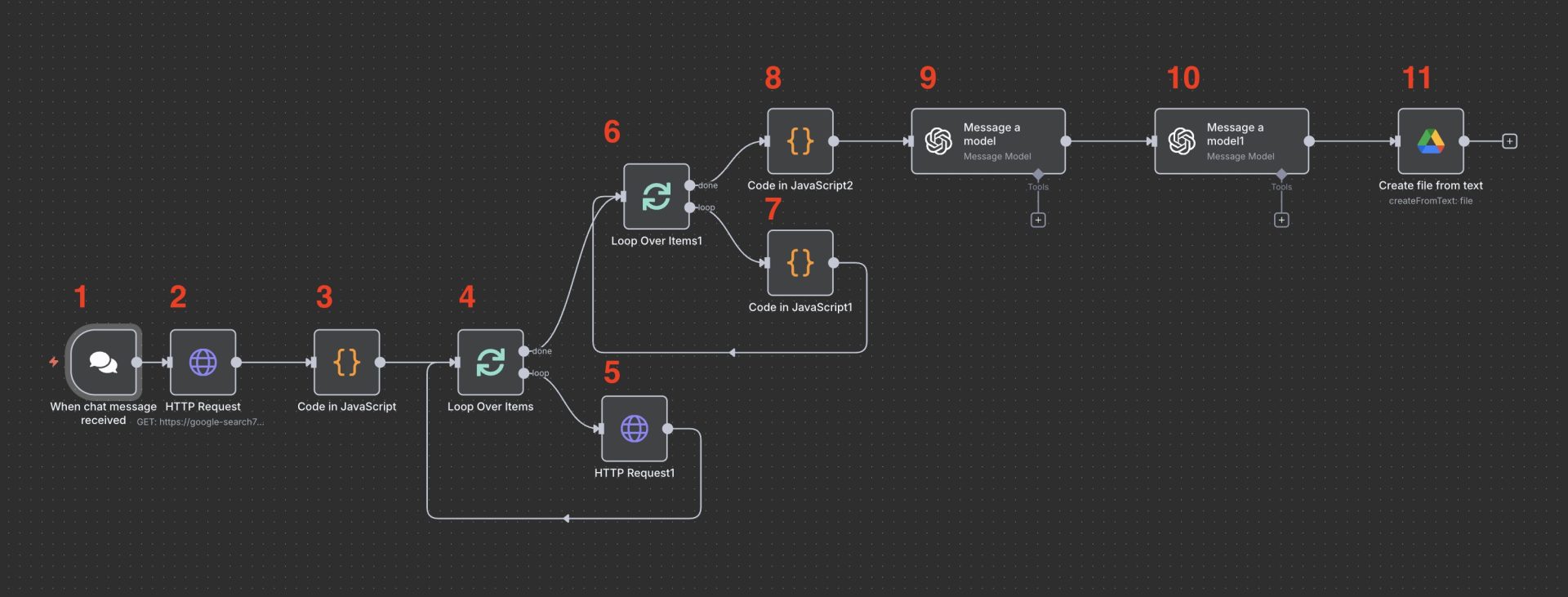
目次
2. HTTP Request
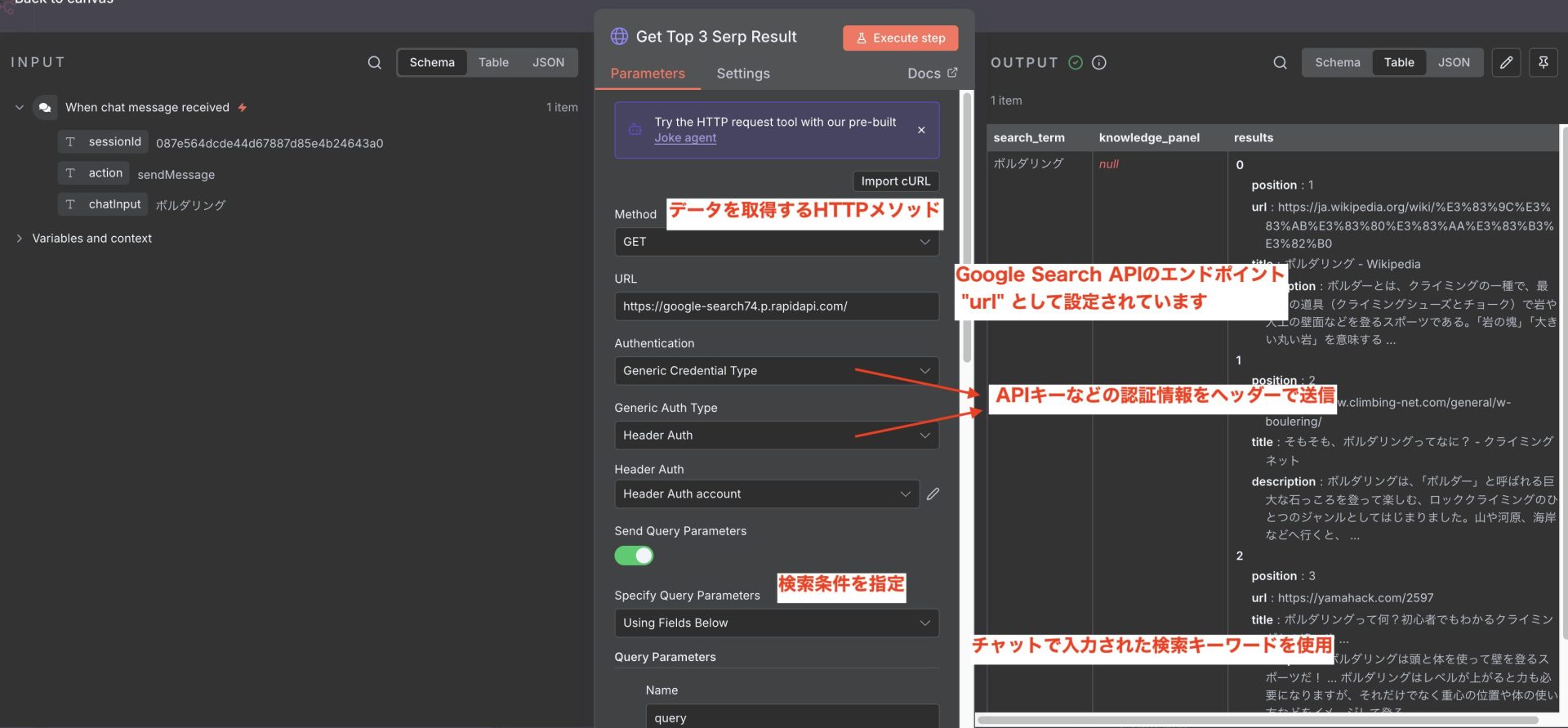
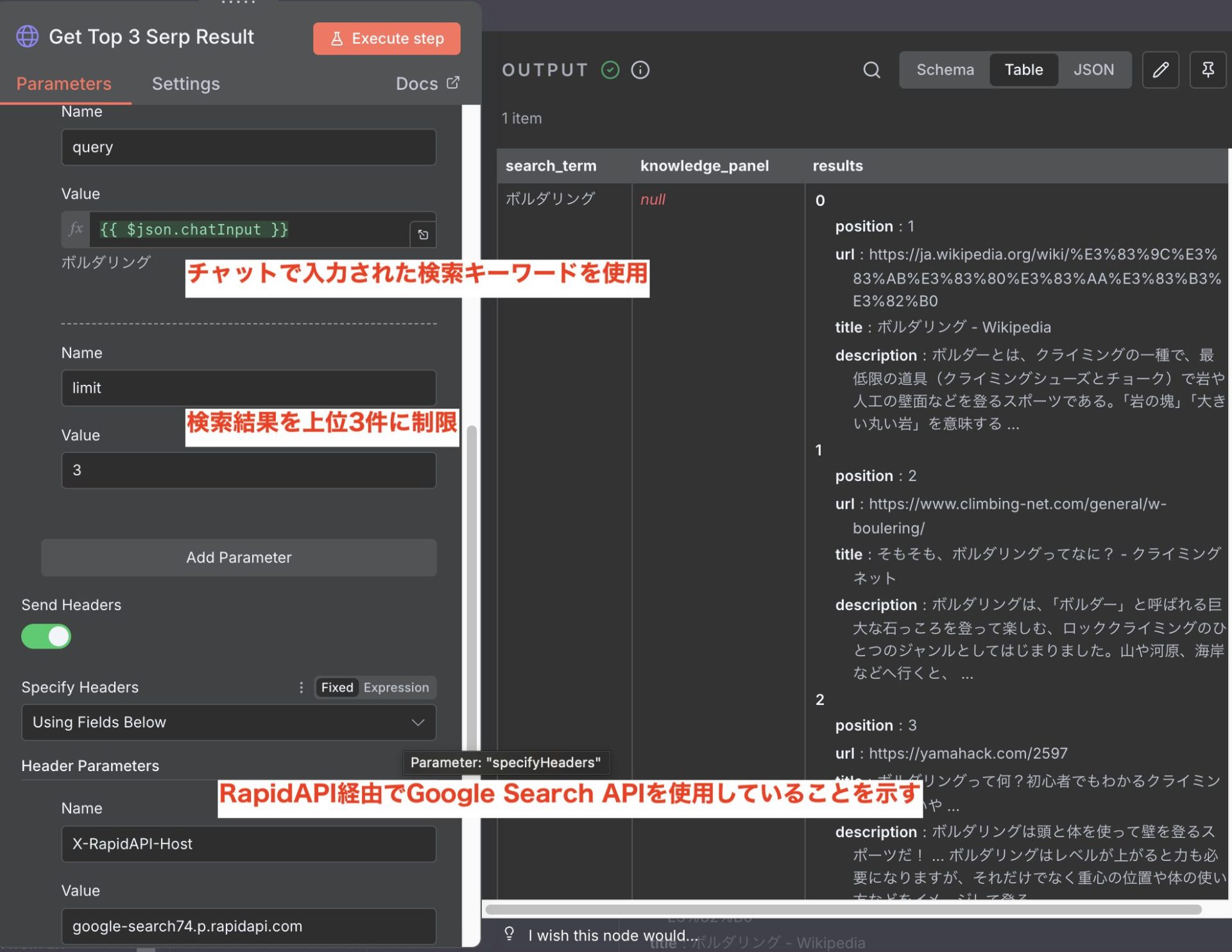
右の各結果にはposition(順位)、url、title、descriptionが含まれています。
このノードは、ユーザーの質問を受け取り、検索APIを呼び出して結果を返す役割を果たしています。
3. Code
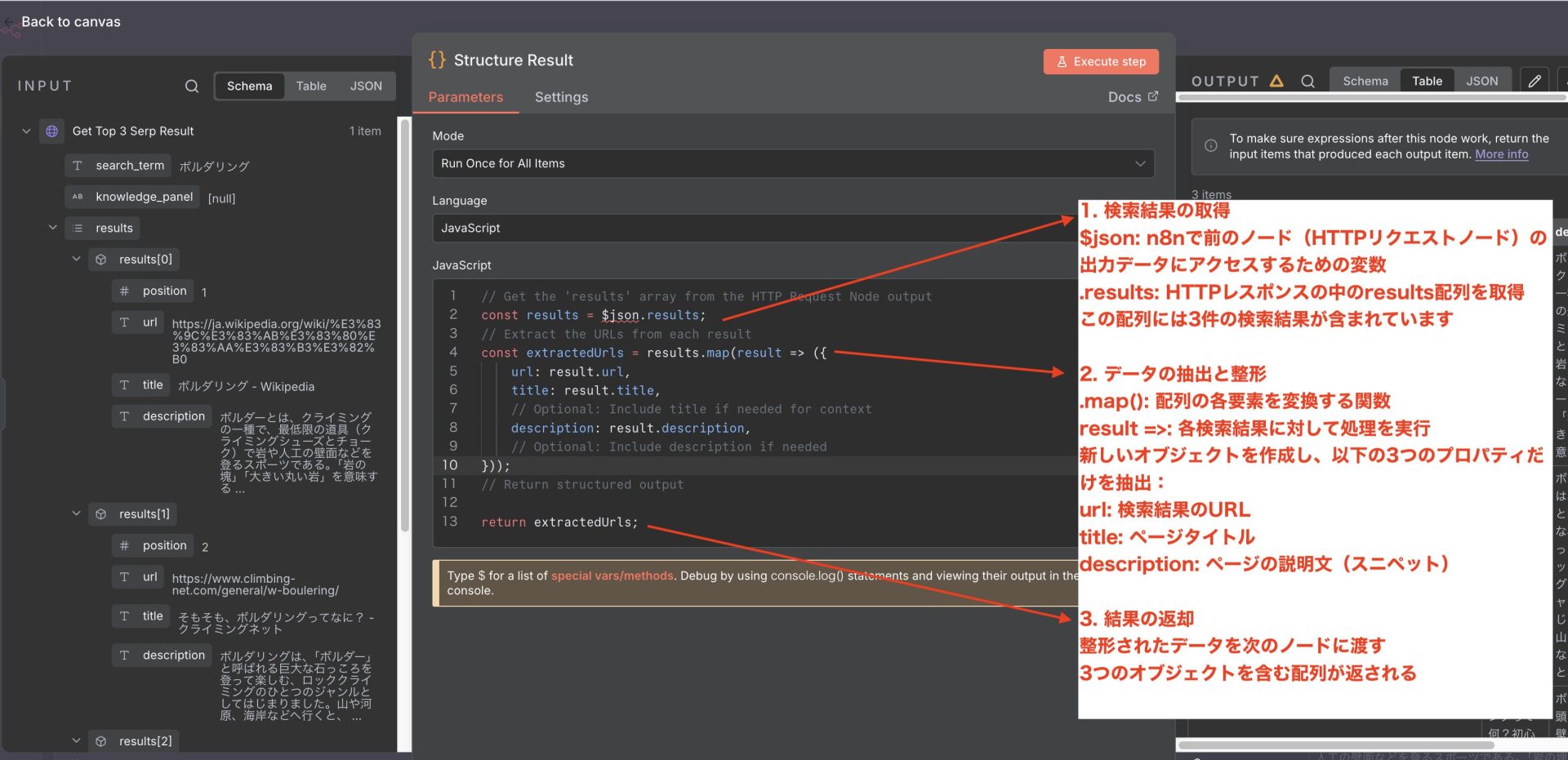
このコードの目的
HTTPリクエストノードの生データには、position(順位)など余分な情報も含まれています。このJavaScriptノードは、次の処理で必要な情報(URL、タイトル、説明文)だけを抽出して、データをクリーンな状態にしています。
この整形されたデータは、例えばAIノードに渡して要約したり、メッセージに整形したりする際に使いやすくなります。
4,6. Loop Over Items
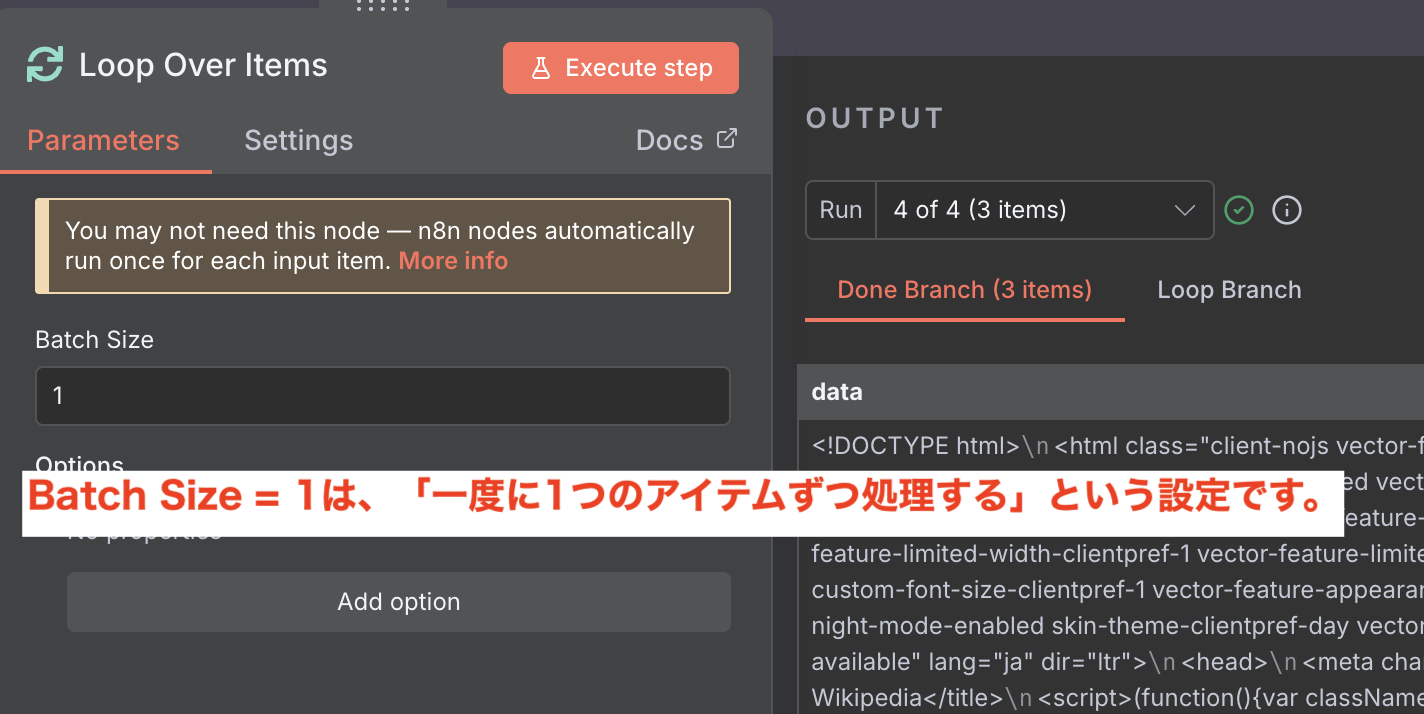
使い分け
Batch Size = 1 を使うケース
- 各URLを個別にスクレイピングしたい場合
- 1件ずつ順番に処理したい場合
- APIのレート制限を避けたい場合
- エラーが起きても他の処理を続けたい場合
Batch Size > 1 を使うケース
- 複数のアイテムをまとめて処理したい場合
- 処理速度を上げたい場合
ワークフローでは
検索結果の各URLを1つずつスクレイピング(Webページから情報を自動的に抽出・収集する技術)するため、Batch Size = 1が適切です。これにより、1件目のURL → 2件目のURL → 3件目のURLと順番に処理されます。
5. HTTP Request
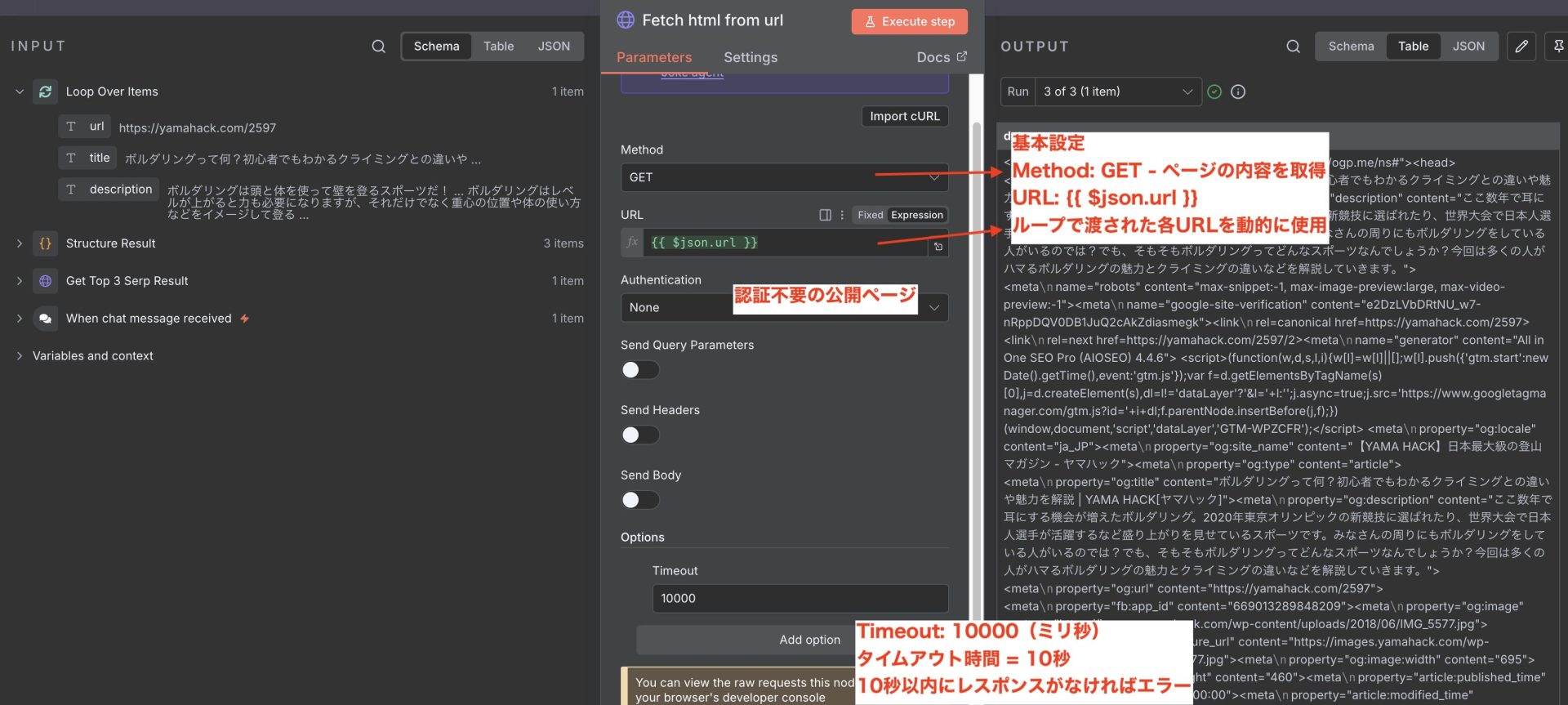
このノードは、検索結果のURLリストから実際のページ内容を取得するスクレイピングです。
7. Code
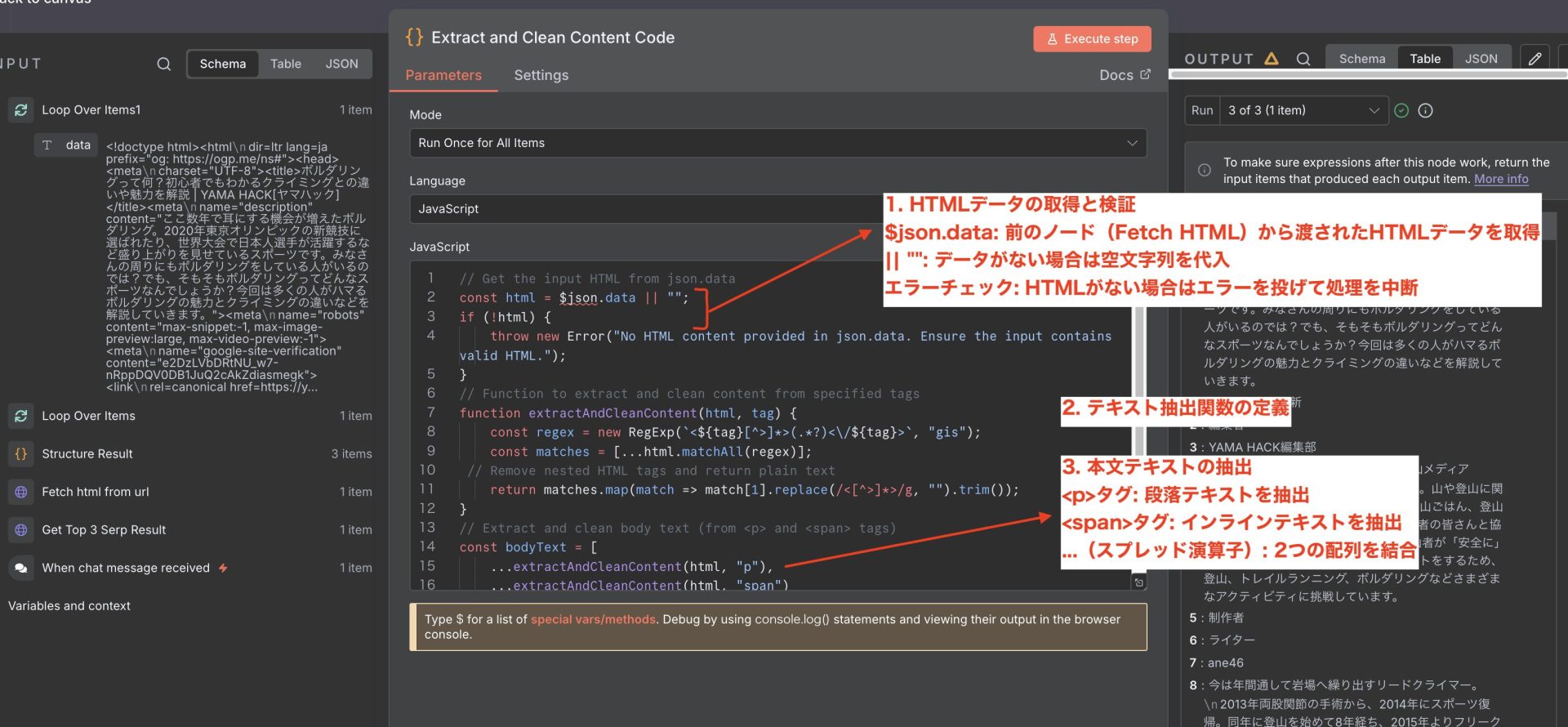
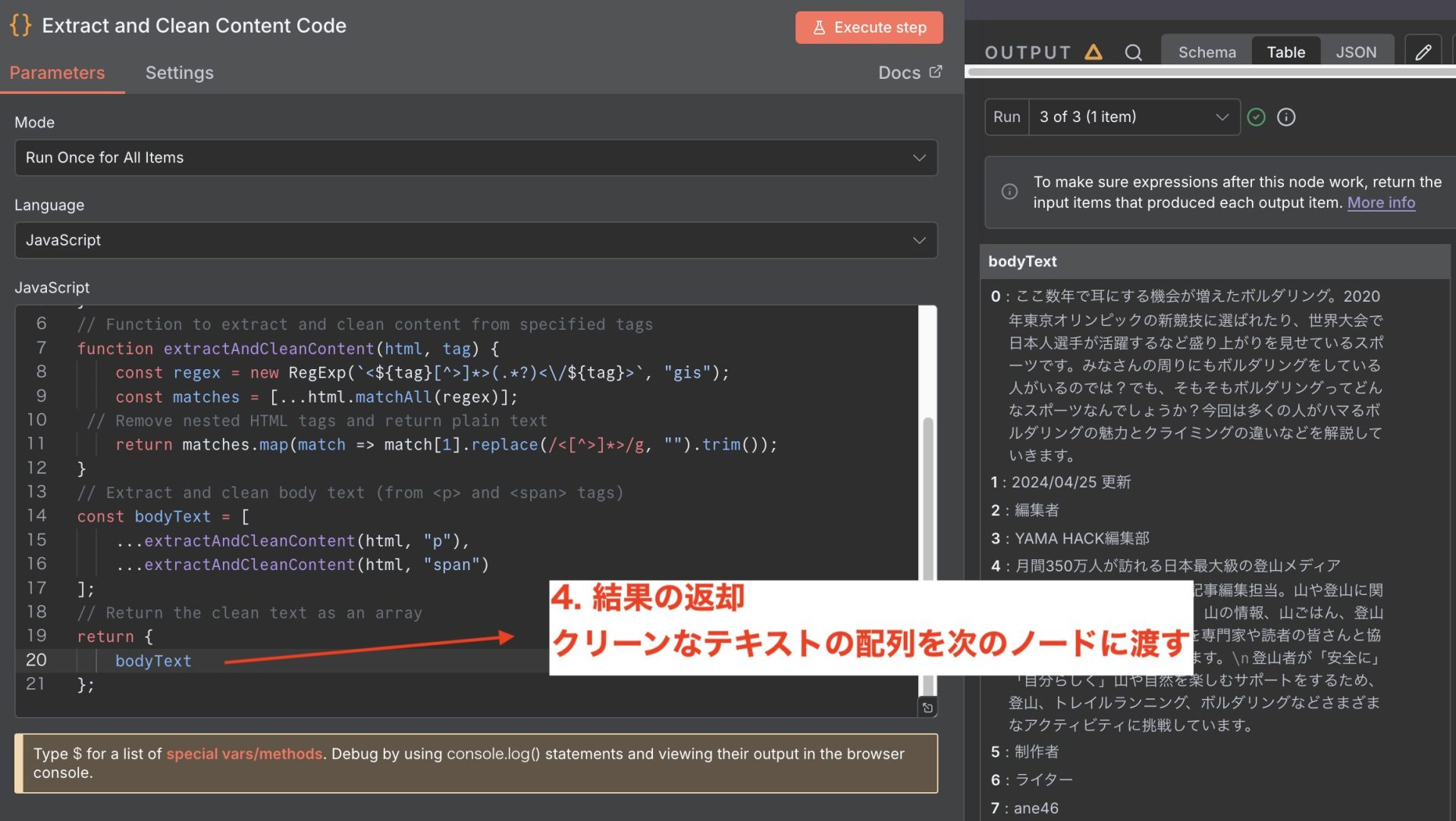
このコードの目的
HTMLのスクレイピング結果から:
- 本文だけを抽出(
<p>、<span>) - HTMLタグを削除(
<strong>、<a>など) - 純粋なテキストのみ取得
このクリーンなテキストを、次のノードで要約や分析に使用します。
8. Code
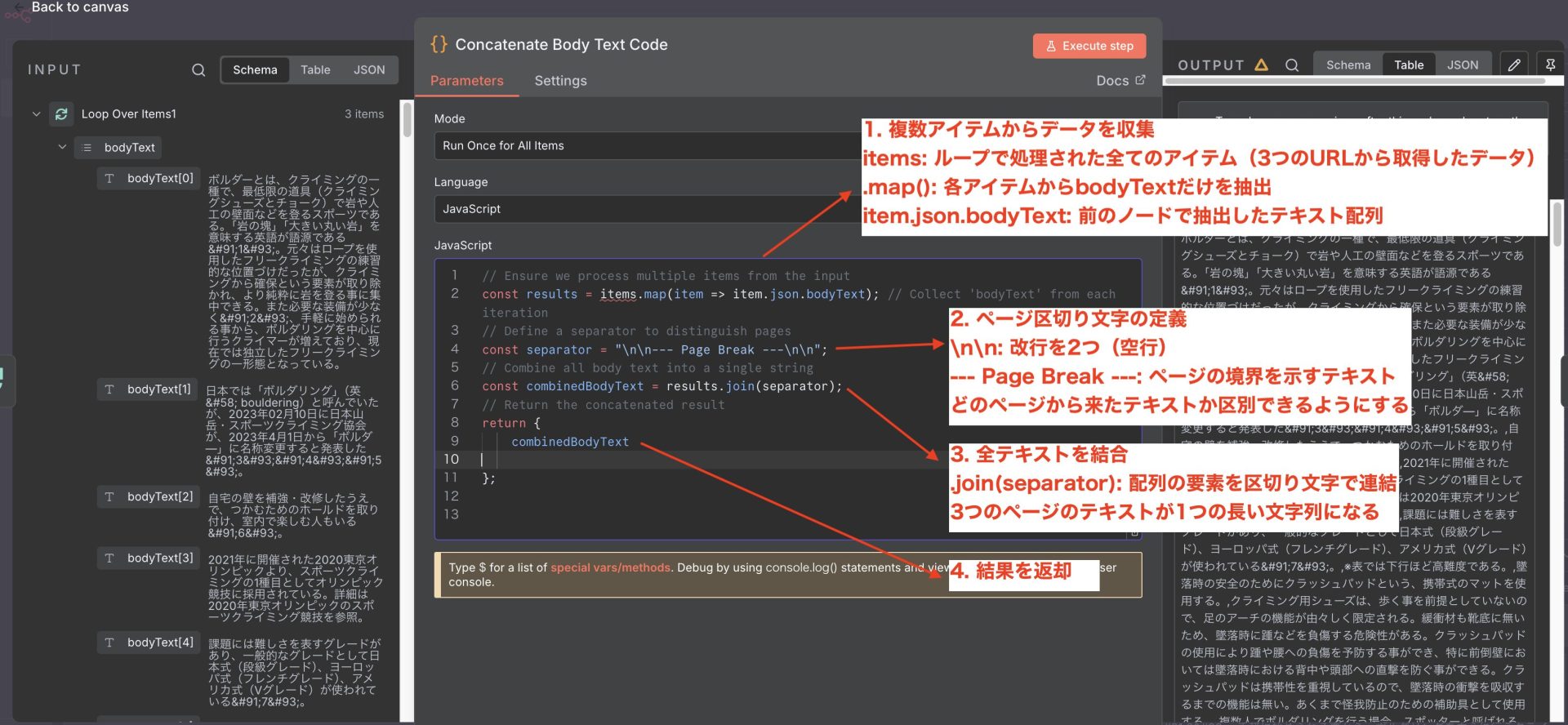
このコードは、ループで取得した複数のページの本文テキストを1つにまとめるJavaScriptです。
9. Open AI
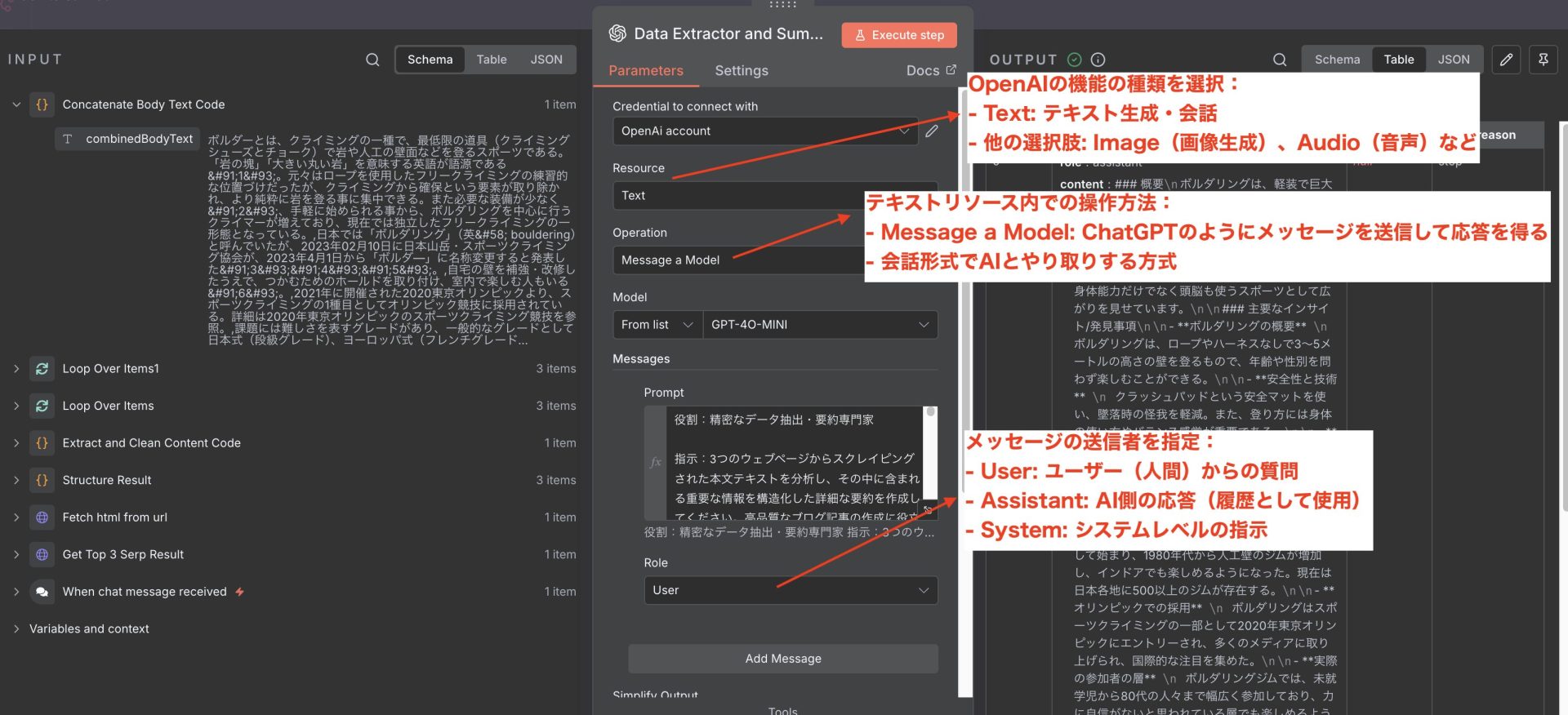
このコードの目的
- どのAIモデルを使うか(Model)
- どんな指示を出すか(Prompt)
- どの形式で応答を得るか(Role, Simplify Output)
完成した記事の例
ボルダリングというキーワードで生成してもらった、記事を添付いたします。
このクオリティで記事が生成されます。画像も自動生成されるとなお良いですね。

最後に
ここでは、SEO対策のためのブログ記事を生成するための、ワークフローの中身を解説しました。
最後のグーグルドライブとの連携など基本設定にあたるところは解説しておりません。大変お手数をかけしますが、他の記事を参考いただければと思います。
それではまたお会いしましょう。
コメント